Oh yeah, it is time. So I have been looking into machine learning and decided I should dive head first into genetic algorithms. The concept was easy enough for me to wrap my head around. As a prefix, this SQF code was based on a python script written by Joeseph Misiti. The source code for that can be found here.
I will not attempt to explain genetic algorithms in this post. I know very little myself. What I will do is show the SQF.
First, let me go over what this does. It generates a specified string from a population of random strings of equal size.
To achieve this, we need to know what makes up each individual string. Characters. So for this reason, a character will be an element within our “dna” strands.
To start, we will need to generate random characters to create a random pool. So writing that function we get:

Next, we’ll need to actually generate our random population. So lets make this function:

Wait, but what are the variables. These are just settings for our algorithm that we can tweak down the road. Here are all of them.

Oh, in this post there will be lest text and more comments. I am sure everyone can read comments.
So next, we will need some way to compare how accurate a random string is to our end goal. This is our fitness function. Mine is simple, but these can be much more complex, even for this scenario.

Okay, before we get into the functions used for “reproduction”. Lets cover how we will judge which “dna” strands can have children to begin with. For this we need to compare each of their fitness values and pick the only the best to have kids. This is know as Survival Of The Fittest and it lays the ground work for evolution and Playerunknown’s Battlegrounds.
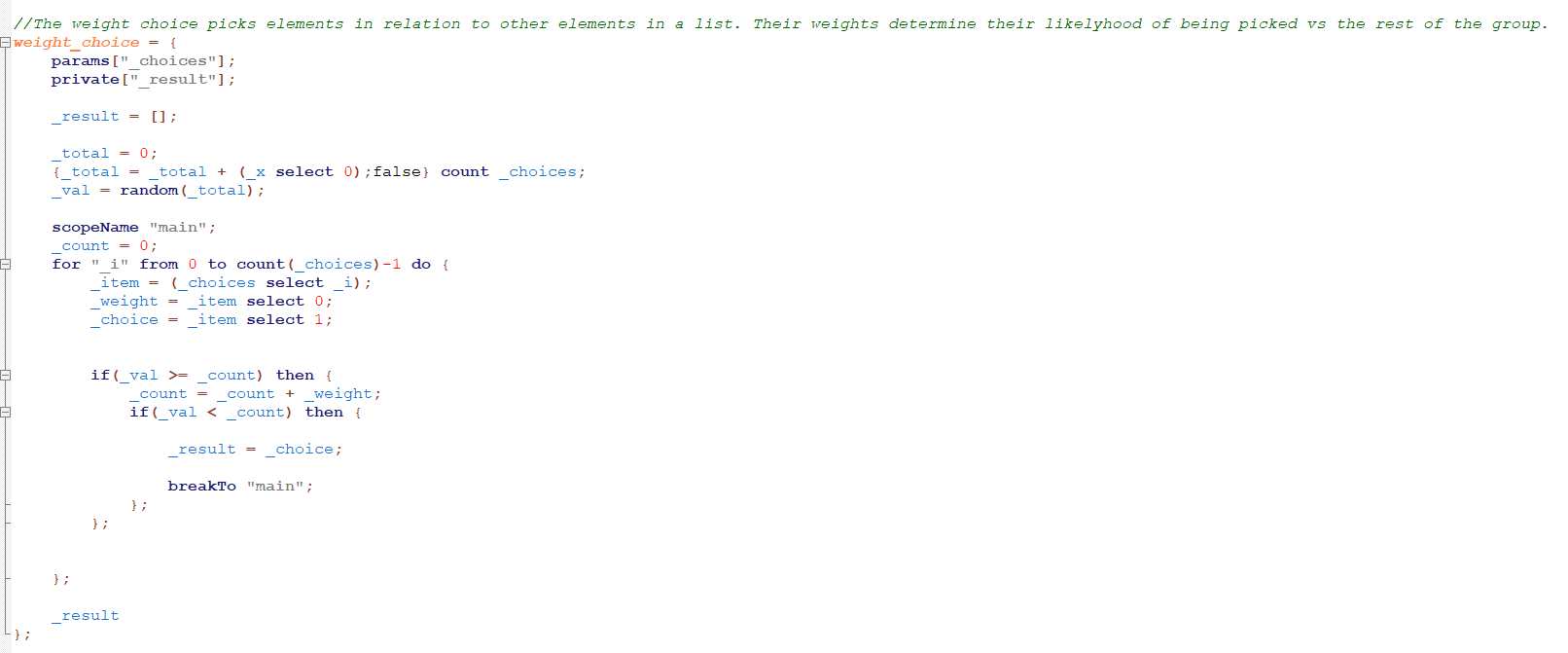
Covering this a bit more. I get the total value of all weights (in this case the weights are the fitness values). I run a random on that value to get a random value between 0 and the total. I then iterate through each item and add their weight to a counter. If that items weight is between the random value and the counter, I know this is the element closest to my random selection.
The way that works is, items with larger “fitness” scores will be more likely to fall within the random values range. Therefore, higher fitness dna strands will be more likely to be selected.
Okay, now that we covered this, lets go over “crossover”. Where two parents come together and if they love each other enough…
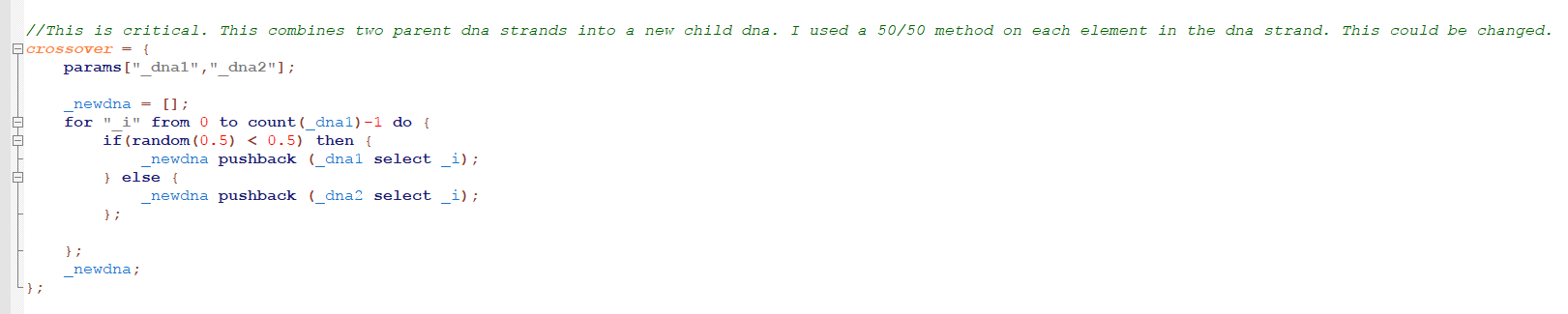
They can make a new DNA strand. The method I decided to go for was the 50/50 method. Each element in the DNA (characters in this case). Have a 50% chance of coming from parent 1 or parent 2. This makes it so two children will more than likely have differing DNA. No twins in this family.
Okay so now we have our two children, but what about mutations? How will we get the X-Men?

With this method we give each dna element a % chance to change to a completely random character. This will give us diversity in our group, so characters not initially included in our DNA pull can be introduced.
Lastly is the hunk of code that actually does the work. Its so much I can’t fit it on one screenshot.
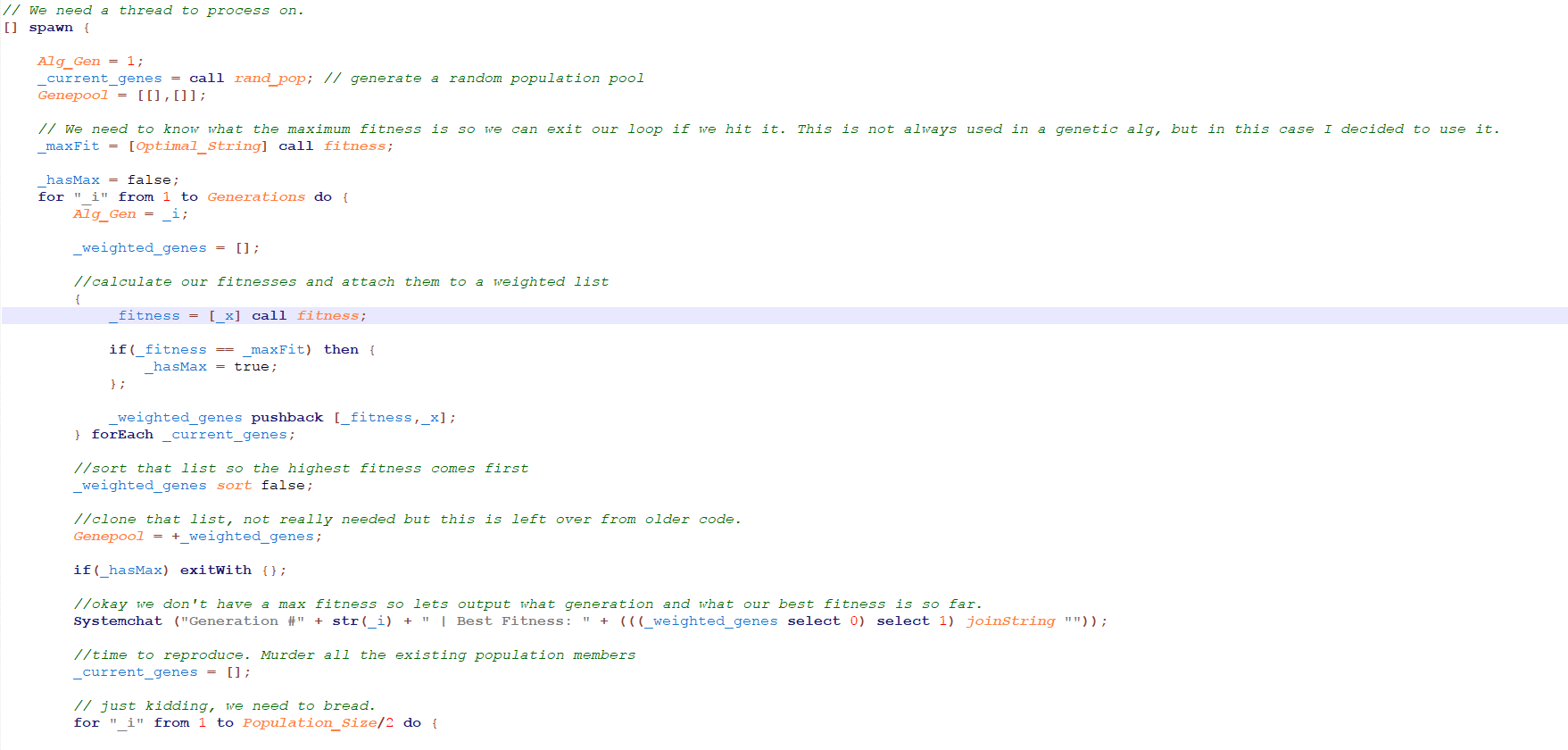
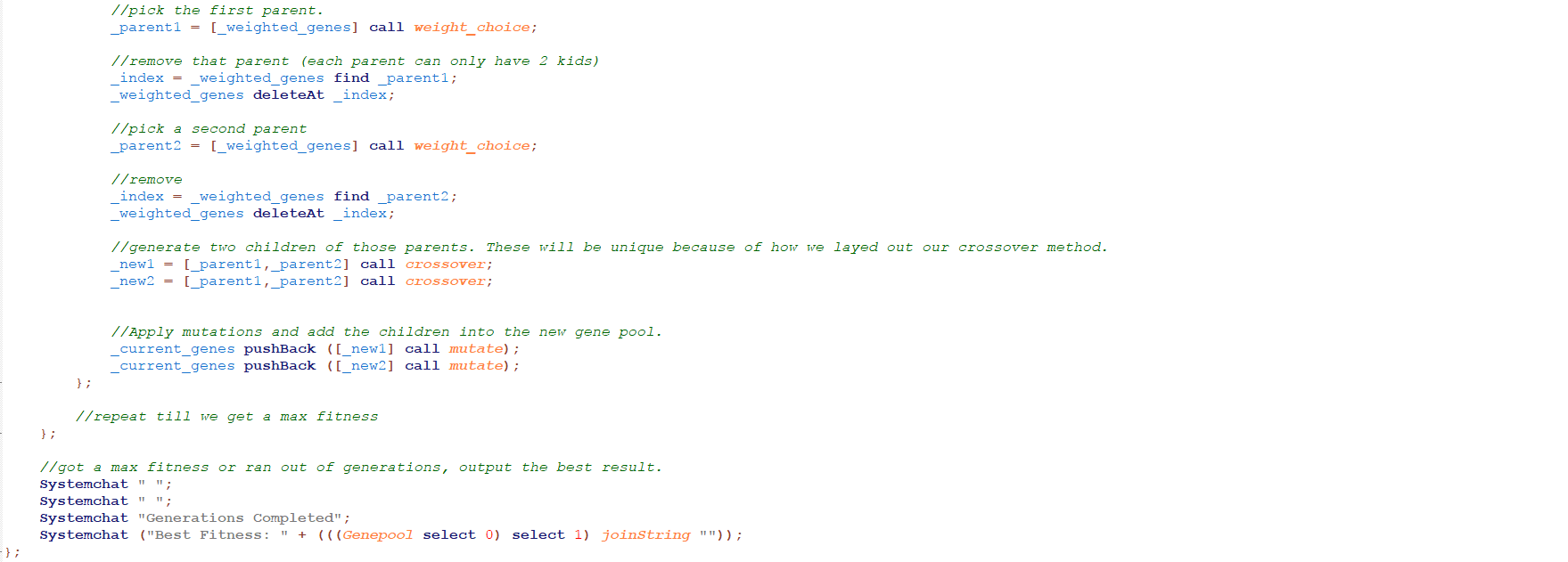
The comments in this code should apply the logic. We simply iterate through our generations, generate fitness values of our generation, reproduce, and repeat until we get our desired result.
Again, this is my first attempt at this. It works, so I guess I did an okay job. The source download is below. Let me know what you think and what improvements I can make.
Answering your last questions, yes this is completely pointless, and yes I will be doing it again.